Recentemente ho scoperto Bitbucket. Per chi non lo conoscesse, si tratta di un’alternativa al più famoso GitHub.
Il vantaggio di Bitbucket è che ti permette di creare repositories privati gratuitamente (a differenza di GitHub).

Questo tutorial ha l’obiettivo di spiegare, per chi ancora non lo conoscesse, cosa è e come si usa Git, l’ormai celebre sistema di controllo di versione scritto (almeno inizialmente) da Linus Torvalds.
Prima di parlare di GIT è molto importante sottolineare cosa è un VCS.
Il controllo della versione è un sistema che registra le modifiche nel tempo ad un file (o ad un gruppo di files) in modo da poter, eventualmente, richiamare versioni specifiche più tardi.
Un VCS consente di: ripristinare i files (o l’intero progetto) ad uno stato precedente, confrontare i cambiamenti nel corso del tempo, vedere chi ha eseguito l’ultima modifica, chi ha introdotto un problema e quando, e molto altro . Utilizzando un VCS siamo quindi in grado, attraverso un overhead significativamente ridotto, di ripristinare una versione funzionante del nostro software in caso di pasticci o perdita di files. Il tutto in modo semplice e veloce.
Fondamentalmente un VCS utilizza un “repository”, che è un posto dove sono memorizzati i files sotto controllo di versione. Questo repository in genere si trova su un server, ma può anche essere riportato sulla propria macchina. L’idea principale di un VCS ruota attorno il seguente processo:
Fino a qualche tempo fa i due sistemi di controllo di versione più popolari erano sicuramente CVS (Concurrent Versions System) e SVN (Subversion).
Si tratta di sistemi di versione centralizzati in cui si ha un singolo server che contiene tutte le versioni di un file, e un certo numero di clienti che eseguono il check-out di files da quel posto centrale. Per molti anni, questo è stato lo standard per il controllo di versione.
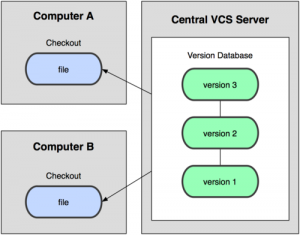
[box type=”note”]Un check-out crea una copia locale dal repository. Un utente può specificare una revisione specifica oppure ottenere l’ultima. Il repository è dove i files sono memorizzati, spesso su un server.[/box]
Git è un sistema di controllo di versione distribuito.
La parola “distribuito” significa che non esiste un server centrale in cui viene memorizzata tutta la storia del codice sorgente di un progetto. Quando un progetto Git viene clonato (“clone” è la parola che Git usa per il checkout iniziale di un progetto), si riceve tutta la storia del progetto, dallo stato attuale fino ai suoi “albori”. Si avrà così l’intero progetto memorizzato in locale sul nostro computer.
Git è scritto in C, riducendo così l’overhead di runtime dei linguaggi di alto livello, inoltre con Git, quasi tutte le operazioni vengono eseguite a livello locale, dando un vantaggio enorme in velocità rispetto ai sistemi centralizzati che costantemente devono comunicare con un server da qualche parte.
Velocità e prestazioni sono stati un obiettivo primario del progetto Git fin dall’inizio.
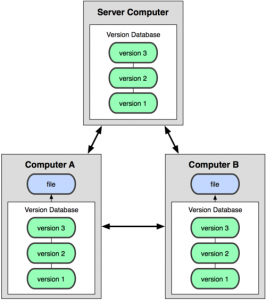
[highlight]In un sistema distribuito di VCS non si ha alcun server centrale che memorizza i dati. Ogni copia locale contiene la storia completa del codice sorgente.[/highlight]
Git, a differenza dei precedenti VCS, non salva le informazioni come una lista di cambiamenti apportati ai files ne tempo, ma considera i propri dati come una serie di istantanee (snapshot) della directory di lavoro.
Ad ogni commit, in pratica, Git salva un’immagine di tutti i files del progetto. Per essere efficiente non immagazzina nuovamente i files che non sono cambiati, ma crea un collegamento agli stessi files, già immagazzinati, nella versione precedente.
Prima di cominciare con un esempio concreto è importante capire l’ambiente in cui Git opera.
Immaginalo come a tre alberi, o sezioni a cui corrispondono altrettanti stati.
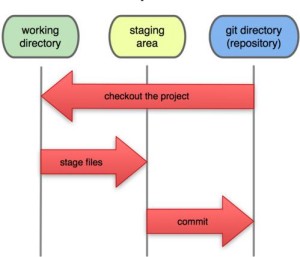
Come detto ad ognuna di queste sezioni possiamo far corrispondere uno stato.
Probabilmente, il principale vantaggio sull’utilizzo di un sistema di controllo di versione durante lo sviluppo del software (o lo sviluppo di qualsiasi documento) è dato dalla possibilità fornita a più persone di lavorare sullo stesso insieme di documenti allo stesso tempo, e riducendo al minimo i problemi di conflitto di editing.
A questo punto potresti obiettare…. ma se sono da solo a lavorare su un progetto (anche un banale sito web), perché dovrei perdere tempo con il controllo di versione visto che nessun altro potrà sovrascrivere il mio codice?
Considera questa situazione comune:
cosa succede se se mi accorgo che le modifiche che ho fatto non vanno bene e volessi tornare al punto 2? Se avessi fatto tutto lo stesso giorno potrei risolvere con una serie di UNDO (sempre che non abbia chiuso il mio IDE).
Ma se avessi fatto le modifiche in giorni diversi?
Con Git non perderai nessuna modifica fatta al tuo progetto. Git tiene traccia di tutte le versioni. Pertanto, è possibile tornare a qualsiasi punto della storia del tuo codice sorgente. Questo non lo ritieni un valido motivo?
Bene, ora che sappiamo (a grandi linee) cosa è un sistema di controllo di versione e soprattutto cosa è Git vediamo come concretamente possiamo utilizzare un’arma tanto potente ed utile.
Tengo a precisare che quello che ti sarà mostrato è un utilizzo base di Git, rimando alla documentazione ufficiale per eventuali approfondimenti.
[box type=”note”]Il codice sotto riportato è stato eseguito su macchina Linux (Ubuntu). Non dovrebbe esserci tuttavia nessun problema nell’eseguirlo su ambiente Windows (o Mac).[/box]
Gli gli utenti di Ubuntu/Debian o distribuzioni similari (Linux Mint, Kubuntu etc.) potranno utilizzare il seguente comando per installare Git sulla propria macchina:
$ sudo apt-get install git-core
Gli utenti Windows potranno invece scaricare il setup a questo indirizzo: http://msysgit.github.com/
Inoltre sempre per gli utenti Microsoft, potranno lavorare andando sulla directory del progetto e con il tasto dx cliccare su Git Bash. si aprirà una finestra di una shell testuale che useremo per gestire Git.
La prima volta che installiamo Git è bene eseguire delle configurazioni generali che saranno memorizzate sulla home directory utente nel file .gitconfig.
In primis è bene far conoscere a Git chi sarà ad eseguire le modifiche, in modo che possa memorizzare tale info su ogni commit.
$ git config --global user.name "Tuo Nome" $ git config --global user.email "tua-email@gimail.com"
Attenzione che questo setup è globale, quindi applicato su ogni repository. Se si vuole usare un’identità diversa su un repository specifico, usare lo stesso comando senza --global dalla directory di lavoro:
$ cd my_repo $ git config user.name "Altro Nome" $ git config user.email "altra-email@gmail.com"
Il seguente comando ci permette di attivare qualche highlighting per la console, aiutandoci nella lettura dei risultati:
$ git config --global color.ui true
Per vedere le impostazioni di Git eseguire il comando config --list:
$ git config --list user.name=Mio nome user.email=mia-email@gimail.com color.status=auto color.branch=auto color.ui=true color.diff=auto
oppure possiamo vedere una configurazione specifica con git config {chiave}:
$ git config user.name Mio nome
Bene, eseguite le configurazioni iniziali, possiamo inizializzare il nostro repository locale. Partiamo con la creazione della directory project01:
$ mkdir project01 $ cd project01
Per creare il repository da quella directory, eseguire il comando init.
$ git init
questo comando creerà un sottodirectory chiamata .git che conterrà uno scheletro del repository Git.
[box type=”note”]Raramente, se non mai, avrete bisogno di fare qualcosa dentro la directory .git difatti è nascosta di default. Si tratta del luogo dove, accade “tutta la magia di Git”.[/box]
Possiamo anche scegliere di clonare un repository esistente, che di solito corrisponde ad un repository remoto. In questo caso dobbiamo usare il comando clone:
$ git clone git://github.com/simogrima/primo-test.git
il comando creerà la directory “primo-test”, con tutti i files del progetto, e la directory .git con il repository. Se vuoi clonare il repository in una directory con un nome diverso, per esempio “foo” puoi specificarlo così:
$ git clone git://github.com/simogrima/primo-test.git foo
[box type=”note”]I repository remoti sono versioni di progetti che sono ospitati in Internet o su una rete da qualche parte.[/box]
Attraverso il comando status di Git possiamo monitorare lo stato attuale del repository:
$ git status # On branch master # # Initial commit # nothing to commit (create/copy files and use "git add" to track)
nel nostro caso visto che non esiste nessuna modifica (la directory di lavoro è vuota) riceveremo un messaggio che ci dice che non c’è niente da commettere. Non ci sono modifiche in sospeso da registrare.
[box type=”note”]Ti troverai ad eseguire il comando git status più spesso di quello che pensi. Anzi è salutare eseguirlo spesso. A volte le cose cambiano senza che ce ne accorgiamo.[/box]
Ora non ci rimane che creare un nuovo file e controllare se Git si accorge del cambiamento rilanciando il comando status:
$ touch file1.txt $ git status # On branch master # # Initial commit # # Untracked files: # (use "git add ..." to include in what will be committed) # # file1.txt nothing added to commit but untracked files present (use "git add" to track)
come possiamo notare Git si è accorto della presenza di un nuovo file non “tracciato”, cioè non presente nell’ultima immagine (commit) consigliandoci anche il comando per eseguire il tracciamento (git add).
Prima di eseguire il commit è necessario aggiunge le modifiche all’indice. Possiamo farlo con il comando add indicando espressamente il file da aggiungere:
$ git add file1.txt
oppure far aggiungere automaticamente a Git tutti i cambiamenti (la soluzione più probabile)
$ git add .
a questo punto siamo in grado di eseguire il nostro primo commit al repository… tuttavia prima di farlo consideriamo qualche ulteriore modifica.
[box type=”note”]Digitando git add . il punto rappresenta la directory corrente, quindi viene aggiunto tutto quello che si trova in essa e tutto ciò che è sotto.
Il comando add (come tutti i comandi Git) è più potente di quello che pensiamo. Per esempio con git add '*.txt' siamo in grado di aggiungere tutti i files con estensione txt.
[/box]
Per capire meglio come Git lavora tra le varie sezioni, eseguiamo qualche ulteriore modifica. Aggiungiamo un nuovo files:
$ touch file2.txt $ git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached ..." to unstage) # # new file: file1.txt # # Untracked files: # (use "git add ..." to include in what will be committed) # # file2.txt
Come possiamo notare ora git status ci mostra il file1.txt aggiunto all’indice e pronto per essere committed mentre il file2.txt non ancora tracciato. E’ importante capire che file2.txt non entrerebbe nel prossimo commit.
Rilanciamo il comando add ed inseriamo anche questo file nell’area di sosta (parcheggio):
$ git add . $ git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached ..." to unstage) # # new file: file1.txt # new file: file2.txt #
Bene, a questo punto eseguiamo una modifica a file1.txt e vediamo cosa succede:
$ echo "Questa e' una modifica a file1" > file1.txt $ git status # On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached ..." to unstage) # # new file: file1.txt # new file: file2.txt # # Changes not staged for commit: # (use "git add ..." to update what will be committed) # (use "git checkout -- ..." to discard changes in working directory) # # modified: file1.txt #
Questo esempio è stato aggiunto per far capire un’ulteriore concetto. Se modifichi un file dopo che hai lanciato git add, devi nuovamente avviare git add per parcheggiare l’ultima versione del file, altrimenti l’ultima modifica non entrerà nel commit successivo.
Eseguire il commit lo possiamo paragonare a registrare un’istantanea dello stato attuale del progetto nel repository.
Ad ogni commit è necessario aggiungere un messaggio (breve ma allo stesso tempo informativo) del motivo della modifica.
Come prima cosa rilanciamo il comendo git add per aggiungere anche l’ultima modifica nell’area di stage:
$ git add .
ora possiamo eseguire il commit:
$ git commit -m "Primo Commit" [master (root-commit) 33b5b05] Primo Commit 1 files changed, 1 insertions(+), 0 deletions(-) create mode 100644 file1.txt create mode 100644 file2.txt
l’opzione -m ci permette di aggiungere direttamente il commento nel comando di commit.
[box type=”note”]Ricordati che qualsiasi modifica non parcheggiata — qualsiasi file che hai creato o modificato e per cui non hai fatto git add — non andrà nel commit.[/box]
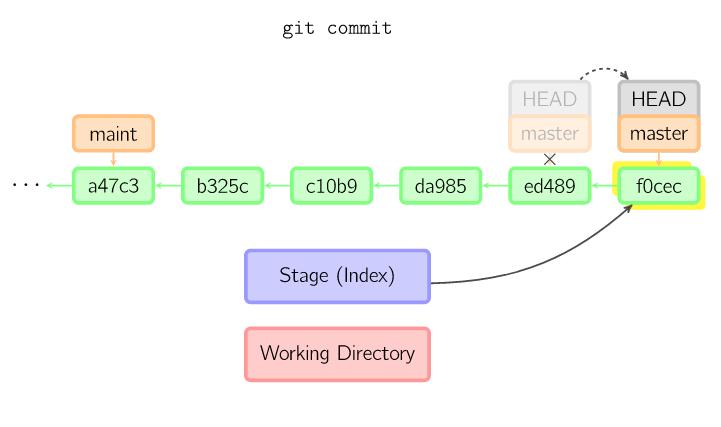
Prima di passare al prossimo argomento, devi capire che ogni commit crea un oggetto nel repository al quale sarà possibile accedere in qualsiasi momento grazie al suo hash. Se non sai cosa sia, considera l’hash del commit come la sua impronta digitale, una sorta id ID univoco creato con un apposito algoritmo (SHA-1) in base al suo contenuto. In generale ogni stringa (oggetto, files etc..) avrà un’impronta (hash) di dimensioni fisse (in base all’algoritmo con il quale è creato).
L’HEAD è un puntatore ad un commit all’interno del repository. Di default HEAD punta al tuo commit più recente, in modo che possa essere utilizzato rapidamente per fare riferimento a tale commit, senza dover cercare il SHA (per la cronaca… HEAD^ punta la penultimo commit, HEAD^^ al terzultimo e così via).
[box type=”note”]Il modo più semplice per rintracciare l’hash di un commit è attrarverso il comando git log --oneline (che vedremo più tardi).[/box]
Se lo desideriamo (io lo faccio spesso) possiamo anche saltare l’area di staging passando l’opzione -a al comando git commit. Modifichiamo il file1.txt e vediamo come eseguire direttamente il commit:
$ echo "Questa è un'altra modifica a file1" > file1.txt $ git commit -a -m "Modificato file1"
Git dispone di un comando più potente (e meno vago) di git status, in grado di farci conoscere esattamente quello che è stato modificato (le linee di codice) e non soltanto i files che abbiamo cambiato. Si tratta di git diff.
git diff senza altri argomenti.git diff --staged.Modifichiamo ulteriormente entrambi i files che compongono il nostro pregetto, e parcheggiamo solo il primo:
$ echo "Questa è la terza modifica a file1" > file1.txt $ echo "Questa è la seconda modifica a file2" > file2.txt $ git add file1.txt
Ora lanciamo il comando git diff e vediamo il risultato:
$ git diff diff --git a/file2.txt b/file2.txt index e69de29..5f5f121 100644 --- a/file2.txt +++ b/file2.txt @@ -0,0 +1 @@ +Questa è la seconda modifica a file2
Il comando compara cosa c’è nella tua directory di lavoro con quello che è nella tua area di stage.
Lanciamo ora git diff --staged:
$ git diff --staged diff --git a/file1.txt b/file1.txt index 34ee54b..8665d9d 100644 --- a/file1.txt +++ b/file1.txt @@ -1 +1 @@ -Questa è un'altra modifica a file1 +Questa è la terza modifica a file1
Questo comando compara i tuoi cambiamenti nell’area di stage ed il tuo ultimo commit.
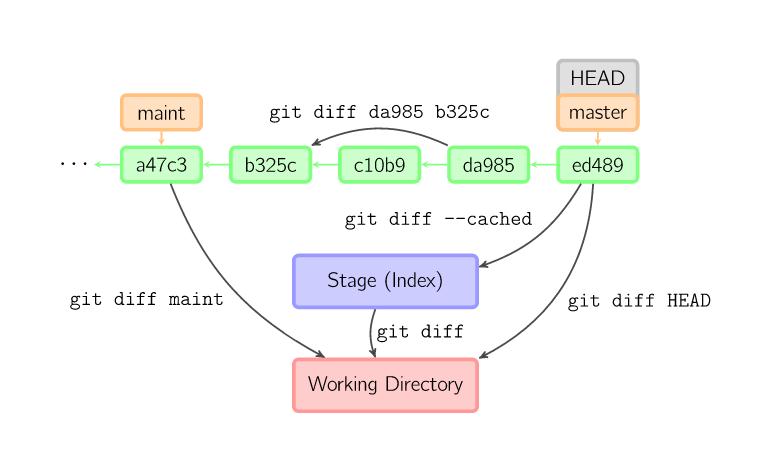
Attraverso il comando git log siamo in grado di vedere la storia del nostro repository, cioè la lista dei commits.
Lo strumento è molto potente e prevede una grande varietà di opzioni che possono essere agginte per perfezionare la visulizzazione. Qua ne vedremo un utilizzo base.
Chiamando git log senza parametri saranno mostrati i commit fatti nel repository in ordine cronologico inverso:
$ git log
commit f8ffb631eabe859cc49bf40ccb6179053a74ab1c
Author: Mio nome <mia-email@gimail.com>
Date: Sun Feb 3 22:36:31 2013 +0100
Nuove modifiche di prova
commit b5da98b64f8d8380fccb6e62eff5c3f711919d1d
Author: Mio nome <mia-email@gimail.com>
Date: Sun Feb 3 21:55:43 2013 +0100
Modificato file1
commit 33b5b054c01c94d3b506274e40ca2730de908922
Author: Mio nome <mia-email@gimail.com>
Date: Sun Feb 3 21:46:35 2013 +0100
Primo Commit
Vedremo ora un’elenco di varianti, di cui per brevità non mostrerò il risultato.
Possimao limitare il numero dei commit mostrati con l’opzione p -n, dove n è un intero:
git log -2
Attraverso l’opzione -p aggiungeremo il diff all’interno del log, ottenendo l’elenco dettagliato delle modifiche x ogni commit (possiamo legarlo al parametro precedente per esempio):
git log -p -2
Possaimo vedere la storia di un sinoglo file aggiungendo il nome come parametro. Il seguente comando mostra le differenze in ogni commit del file filename:
git log -p filename
Il seguente comando mostra il log formattato in un a sola riga:
$ git log --pretty=oneline
[box type=”note”]Attraverso il comando git log --summary possiamo avere una buona panoramica su cosa sta accadendo nel progetto, visto che mostra quando sono stati aggiunti o cancellati dei files.[/box]
La cosa più importante da ricordare quando si lavora con Git è che qualsiasi cosa fatta a Git può essere recuperata.
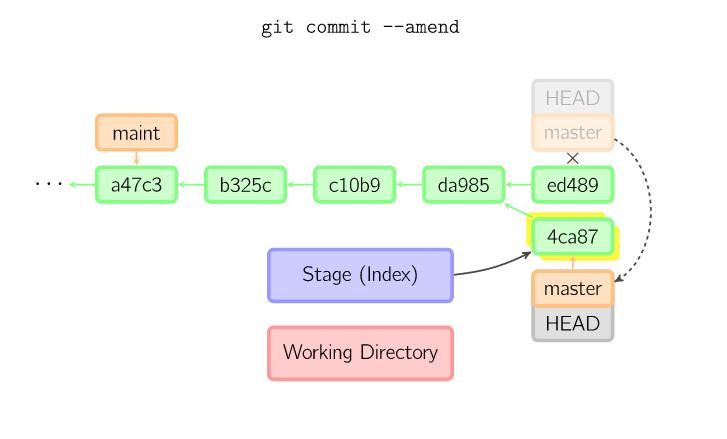
Con il seguente comando siamo in grado do cambiare il messaggio dell’ultimo commit:
$ git commit --amend -m "Nuove modifiche generali"
Più precisamente l’opzione --amend permette di aggiungere al tuo ultimo commit quello che si trova nell’area di stage. Supponiamo che nell’ultimo commit volevamo aggiungerci anche un nuovo file che ci siamo dimenticati di creare:
$ touch file3.txt $ git add file3.txt $ git commit --amend -m "Nuove modifiche generali ed aggiunto file3"
Supponiamo che abbiamo aggiunto erroneamente un file nel parcheggio:
$ echo "Questa e' una modifica a file3.txt" $ git add .
ed ora lo volgiamo disimpegnare dall’area di stage, lo possiamo fare semplicemente con:
$ git reset HEAD file3.txt
L’ultimo annullamento che vedremo è quello relativo alle modifiche nell’area di lavoro (cioè ai files correnti del nostro progetto).
Con il comando git clean possiamo rimuovere i files (ancora non tracciati) dalla directory di lavoro.
echo "Questo file non mi serve" > unnecessary.txt echo "Neanche questo" > unnecessary2.txt git clean -n Would remove unnecessary.txt Would remove unnecessary2.txt git clean -f Removing unnecessary.txt Removing unnecessary2.txt
il comando con l’opzione -n non cancella niente, ma ci mostrerà solamante quello che verrà fatto.
Nel caso invece avessimo modificato (o cancellato un file) e non lo avessimo ancora aggiunto al parcheggio oppure committed, possiamo ripristinare i cambiamenti con il comando checkout:
# cancellazione di un file cat file1.txt Questa è la terza modifica a file1 rm file1.txt git checkout file1.txt # Modifica di un file echo "Questa e' una modifica non voluta a file1" > file1.txt cat file1.txt Questa e' una modifica non voluta a file1 git checkout file1.txt cat file1.txt Questa è la terza modifica a file1 git status # On branch master nothing to commit (working directory clean)
Attraverso il comando checkout possiamo anche ripristinare versioni precedenti del nostro codice attraverso l’ID del commit. Come già detto possiamo ottenere tale ID (hash) attraverso git log:
# Ottengo l'elenco dei commit git log # Checkout della vecchia versione attraverso: git checkout commit_id
Naturalmente Git ti dà la possibilità di ignorare determinati files o directories (di solito i files di log, per esempio, non ha senso metterli sotto controllo di versione).
Puoi farlo aggiungendo il file .gitignore nell’area di lavoro. Vediamo un semplice esempio:
# ignora tutte le directories myDir nell'area di lavoro myDir # ignora tutti i files myFile nell'area di lavoro myFile # ignora il file myFile che si trova nella rott dell'area di lavoro /myFile # ignora tutti i files che terminano per ~ *~
Nel file .gitignore ogni riga rappresenta un pattern. Le linee che iniziano con # rappresentano un commento.
In questo articolo ho cercato di farti capire i vantaggi nell’utilizzo di un sistema di controllo diversione come Git.
E’ chiaro che si tratta solo di un’introduzione, molti concetti come lavorare con repositories remoti, branching, merging o tagging sono stati completamente saltati.
Tuttavia anche se sei da solo, anche se lavorerai sempre in locale i vantaggi sono palesi. Non dovrai più inventarti un metodo per eseguire backups del tuo codice sorgente.
In questo post ti ho mostrato i comandi essenziali per non doverti più preoccupare su come memorizzare (ed eventualmente ripristinare) qualsiasi modifica fatta al tuo codice, dalla notte dei tempi ad oggi.